cwim 背后的故事:Rust 与 Ownership

前几天 Stack Overflow 博客上面有一篇文章1,里面提到了 Rust 已经连续四年位列 Stack Overflow 社区最爱编程语言榜首。的确,Rust 是一门神奇又美丽的语言。Rust 是一门标榜 safe 与 zero-cost abstraction 的语言2,意味着只要你编写的 Rust 代码符合官方标准 —— 能够通过编译 —— 那么你的项目几乎可以肯定地说是内存安全的。
初衷
偏向底层的 Rust 让我在之前一直没有机会尝试,毕竟我相信国内高校没有一所是敢直接抛弃 C、C++ 而使用 Rust 作为其主语言进行授课的。最近我重构了 Dev on Windows with WSL:一个近 2w 字的 WSL 开发配置文档。我前后用了大概半个月的时间,增加了许多内容,因此我在结束编写工作之后,试图找到一个类似 cloc,能帮我统计一个目录下全部 Markdown 文件的命令行工具。很失望,没找到。
我决定自己尝试实现这个命令行工具,当然,我也相信 Python、Node.js、Ruby 等脚本语言一定适合做这些事情,毕竟 cloc 本身就是使用 Perl 实现的。不过,Rust 作为一门高效的、静态的、可以直接编译到三个操作系统的底层语言,还是很有吸引力的。因此我才决定使用 Rust 开新坑。
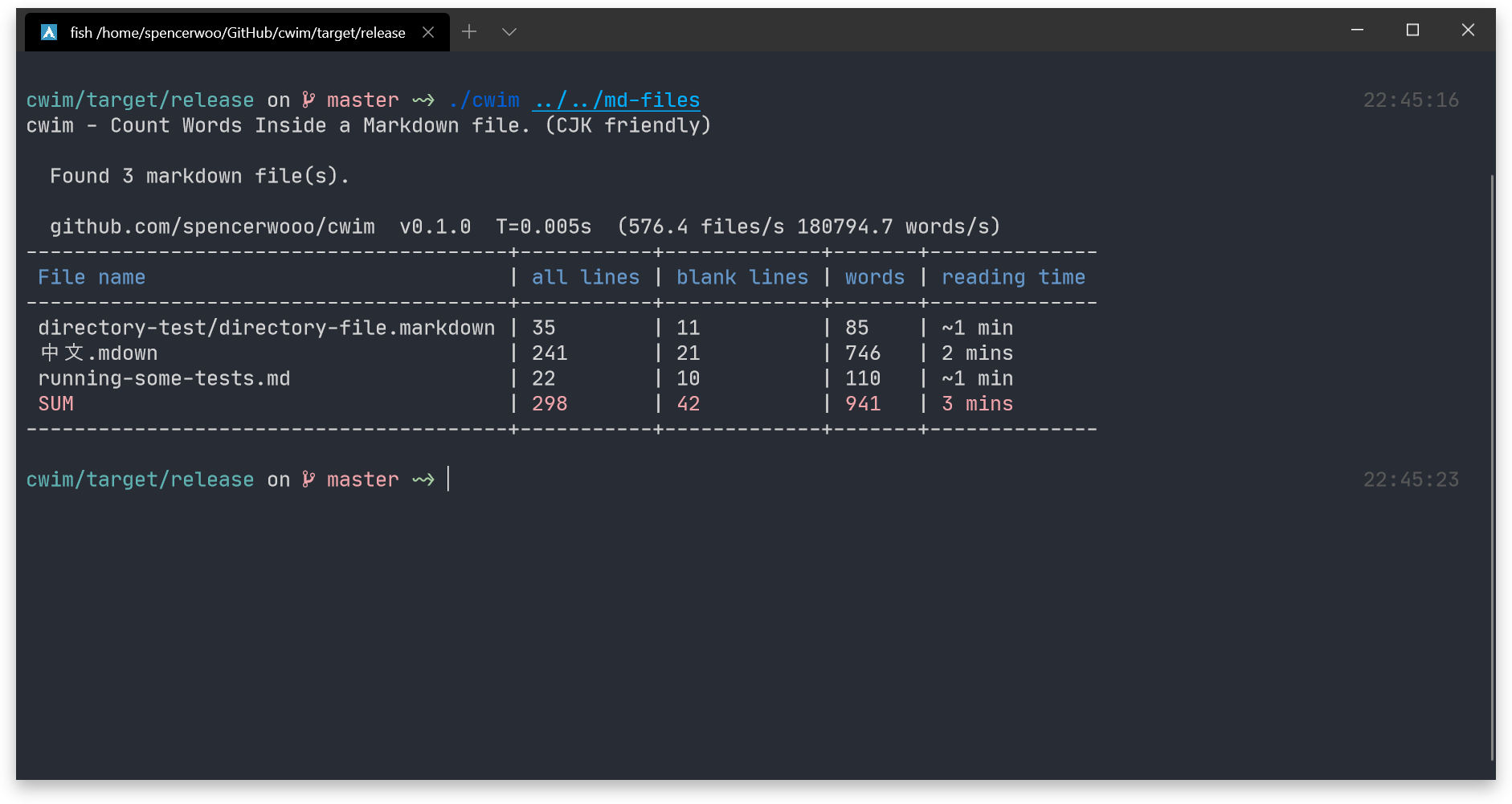
另外:cwim 的第一个小版本我已经编译并发布 Release 版本,有兴趣的同学可以前往 GitHub 查看:spencerwooo/cwim.
开始一个 Rust 项目
Rust 最 beginner friendly 的地方我觉得在于其官方入门文档的简洁易懂。从安装、编译到包管理、打包项目 …… Rust 的官方文档讲解的都比任何其他语言的文档讲解的要易懂不少。我这里简单记录一下 Rust 环境的安装搭建的基本过程。
安装 Rust 环境
Rust 语言虽然小众,但是其生态相当完善。Rust 借鉴了其他语言的多种环境配置工具,官方直接提供了一整套完善的闭环 Toolkit,基本能满足我们在使用 Rust 时的安装、构建、编译、发布的整套流程:
- Rustup:Rust 版本管理(类似 Python 的
pyenv、Node.js 的nvm等) - Cargo:Rust 构建工具与包管理(类似 Python 的
pip、Node.js 的yarn等) - crates.io:Rust 的 Package Registry
首先,我们安装 Rustup:Rust 安装器与 Rust 版本控制器。使用 Arch Linux(以及 WSL 的 Arch Linux)的同学可以直接在 AUR 中安装 rustup:
yay rustup如果使用 WSL 其他 Linux 发行版,我们也可以用下面的命令安装 rustup:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh其他安装方法请参考:Rust | 安装 Rust
安装了 rustup 之后,我们就应该已经安装完成了 Cargo:Rust 的构建工具与包管理工具。Cargo 可以做很多事情:
cargo build # 可以构建项目
cargo run # 可以运行项目
cargo test # 可以测试项目
cargo doc # 可以为项目构建文档
cargo publish # 可以将库发布到 crates.io要检查是否安装了 Rust 和 Cargo,可以在终端中运行:
cargo --version接下来我们就可以使用 Cargo 来创建一个 Rust 项目,并用它来安装我们必须的 Rust 库等内容。
Rust / VS Code
VS Code 是一个通用的文本 / 代码编辑器,能够通过插件支持多种语言环境下代码的编写任务。我们下载 Rust 官方提供的 VS Code 插件:Visual Studio Code Marketplace | Rust (rls)

之后,我们用 Cargo 创建一个新的项目 hello-rust:
cargo new hello-rust或者在已有文件夹 hello-rust 下,生成新 Rust 项目:
cd hello-rust
cargo init新的 Rust 项目目录下应该拥有以下内容:
hello-rust # 根目录
|- Cargo.toml # Rust 的清单文件,其中包含项目的元数据和依赖库
|- src
|- main.rs # 主程序入口用 VS Code 打开这一目录,我们即可开始 Rust 项目的编写。
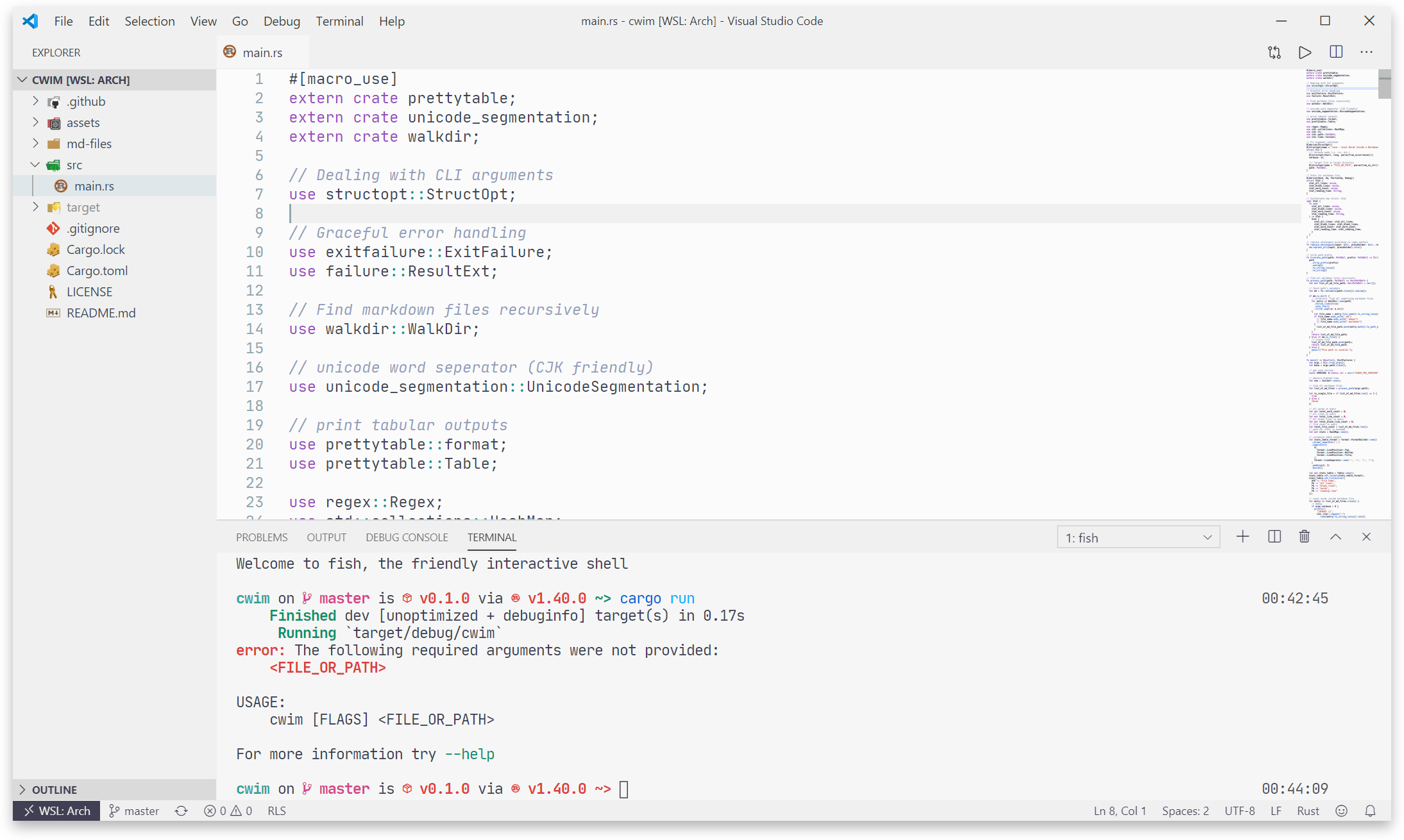
使用下面命令即可运行项目:
cargo runRust 语言特性
在用 Rust 编写 cwim 的时候,有两个令我印象深刻的地方:一个是 Rust 语言实际上非常清晰易懂,有 C、C++ 等强类型语言的严谨,也有脚本语言的易读;另一个就是 Rust 编译器非常严格,但给我们的问题提示也非常清晰,方便追溯问题所在,容易 debug。严苛的 Rust 编译器让我们必须考虑「内存分配」,也正因如此,使得 Rust 在并未实现「垃圾回收」的前提下,确保了任何 Rust 程序都生来具有「内存安全」特性。
🧲 Rust Playground
下面涉及到的代码内容可以在 Rust 在线 Playground 中自己尝试。链接位于:Rust Playground
Ownership
Rust 的 Ownership(所有权)是保证 Rust 程序「内存安全」的重点特性。什么是「内存安全」?保证「内存安全」就是指或语言本身,或使用语言的开发者,在其程序运行时管理系统的「内存分配」的过程中保证内存没有浪费、没有泄露。我们一般的程序都需要实施「静态」与「动态」两种形式的内存分配,其中前者指已知变量所需空间,直接在内存中划分一部分不变的区域给变量;后者为在程序运行过程中动态地给变量分配内存空间,使得变量能够在程序运行时变化地占用内存大小。
数据存储方式
Rust 是使用「栈」和「堆」这两种数据结构来对这两种内存分配形式进行划分的。为了更好的理解 Rust 的 Ownership 的工作机制,我们首先看看 Rust 是如何利用「栈」和「堆」进行内存分配。
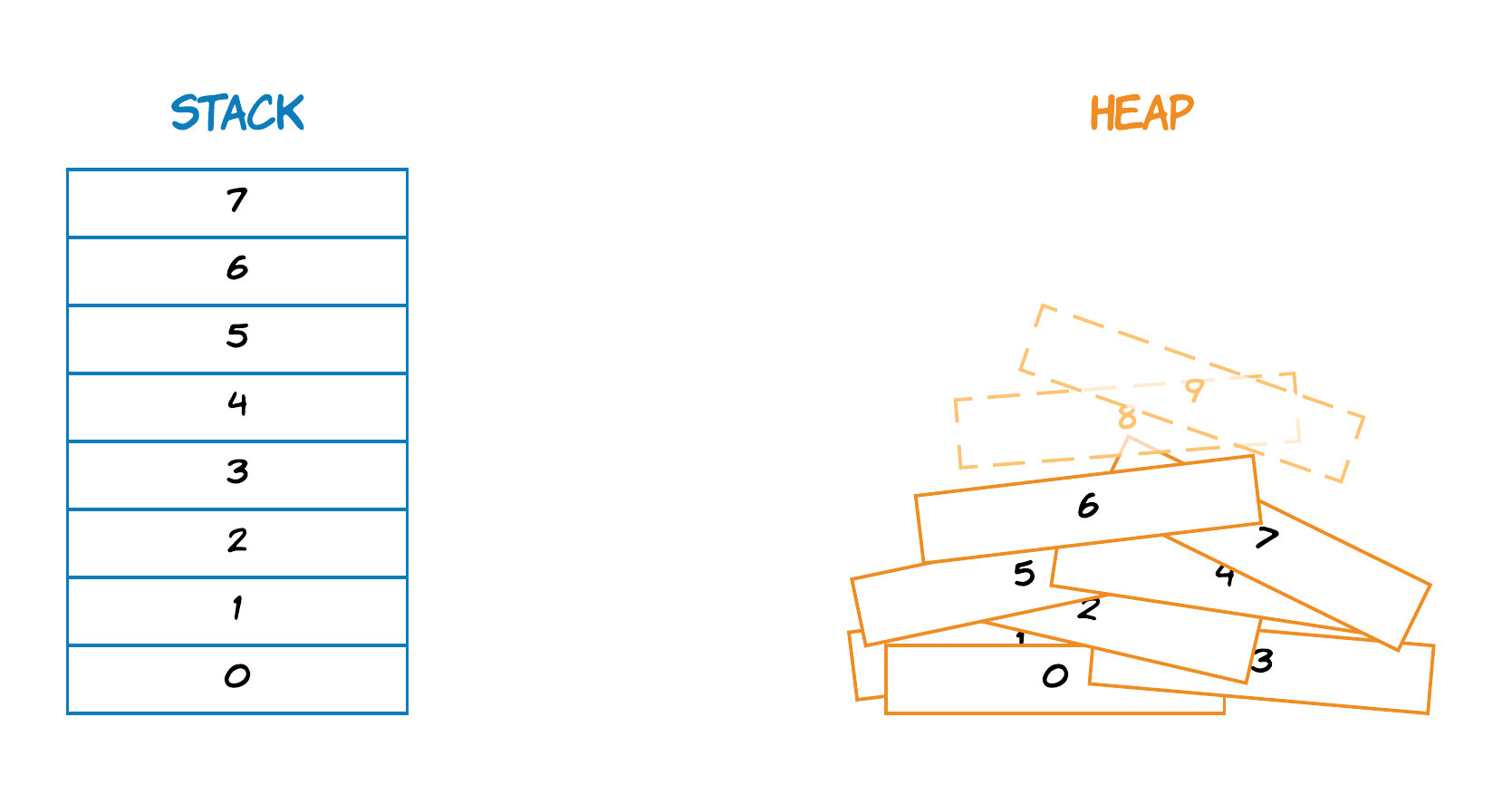
首先,「栈」从实现上来说是一种效率非常高的数据结构,因为「栈」拥有「后进先出」的数据存储特点(LIFO),使得最后压入栈顶的元素会被最先从栈顶移出。这种数据结构的优势在于:当我们用「栈」来维护内存数据时,我们只需要维护「栈顶」元素的信息即可。同时,Rust 内存管理的「栈」在编译时即可知道其具体大小,静态分配内存空间即可3。
而 Rust 的「堆」则不一样,「堆」是一个动态分配内存空间的数据结构。当我们使用「堆」分配内存空间时,我们实际上是在「堆」上寻找对应的内存地址,将之标记,并返回与之相对映的指针。这一过程跟我们 C、C++ 中的 allocate memory 的原理是一致的。
所有权如何保证内存安全
为什么 Rust 需要引入「所有权」的机制?因为 Rust 保证「内存安全」的方法是:追踪第二种「堆」结构中哪部分数据被哪部分代码使用,从而尽量减少「堆」中的重复数据,保证「堆」中不出现有未使用的数据等问题。
Keeping track of what parts of code are using what data on the heap, minimizing the amount of duplicate data on the heap, and cleaning up unused data on the heap so you don’t run out of space are all problems that ownership addresses. —— The Rust Book
Rust 正是使用基于「所有权」理念的一系列规定来保证 Rust 程序的「内存安全」。这其中的机制包括:
- Rust 中的每个「值」都有一个被叫做 owner 的变量(所有者)
- 同一时间只能有一个 owner
- 当 owner 离开我们程序段的 scope 之后,这一「值」就会被释放掉
我们来看下面的几个例子,来具体看看 Rust 如何保证「内存安全」的。
我们以 Rust 中字符串(String Literal)为例子,Rust 中字符串有 &str 的静态字符串变量,以及 String 的动态字符串变量。我们来看看 Rust 是如何分别利用「栈」来存储 &str、用「堆」来存储 String 的。
首先来看一个 &str 的例子:
fn main() {
// &str 用「栈」存储
let s1 = "Hello"; // 字符串 "Hello" 赋值给变量 s1
let s2 = s1; // 将变量 s1 复制并赋值给 s2
println!("{}", s1); // 这样做没有问题!
}可以发现,当我们直接使用 &str 存储字符串时,Rust 是将前一个变量 s1 的值直接复制给后一个变量 s2,前一个变量 s1 并没有变化。此时我们访问前一个变量 s1 没有任何问题。
接下来,我们来看一个 String 的例子:
fn main() {
// String 用「堆」存储
let s1 = String::from("Hello again"); // String 变量 "Hello again" 赋值给 s1
let s2 = foo; // 将 s1 变量中的内容「移动」到 s2 中
println!("{}, {}", s1, s2); // 出错了!s1 中内容被 moved,无法被 reference
}此时,编译器会报出 error[E0382]: borrow of moved value: 's1' 的错误。可以发现,当我们使用 String 存储字符串时,Rust 不会将变量的值「复制」,而是会将变量「移动」到目标变量中。这种情况下,Rust 会认为前一个变量 s1 已经不再有效(no longer valid),因此,当我们在之后试图访问 s1 时,Rust 就会报出这一错误。
![error[E0382] 报错](https://cdn.spencer.felinae98.cn/blog/2020/07/20200722-215236-4.png)
为什么 Rust 在使用「堆」进行动态内存分配时,会 move 而不 copy 呢?一方面是因为 copy 的消耗是比 move 大得多的;另一方面,Rust 这一设计恰好帮助我们避免了 C 语言中非常可能遇到的一种内存泄露的问题:double free 异常4。
Double free 异常是如何发生的?当我们使用 String 类型来存储字符串时,我们实际上存储了以下三个 field 的值:ptr、len、capacity。ptr 指向存储字符串内容的内存空间。比如 let s1 = String::from("Hello"); 即声明了如下的存储方式:
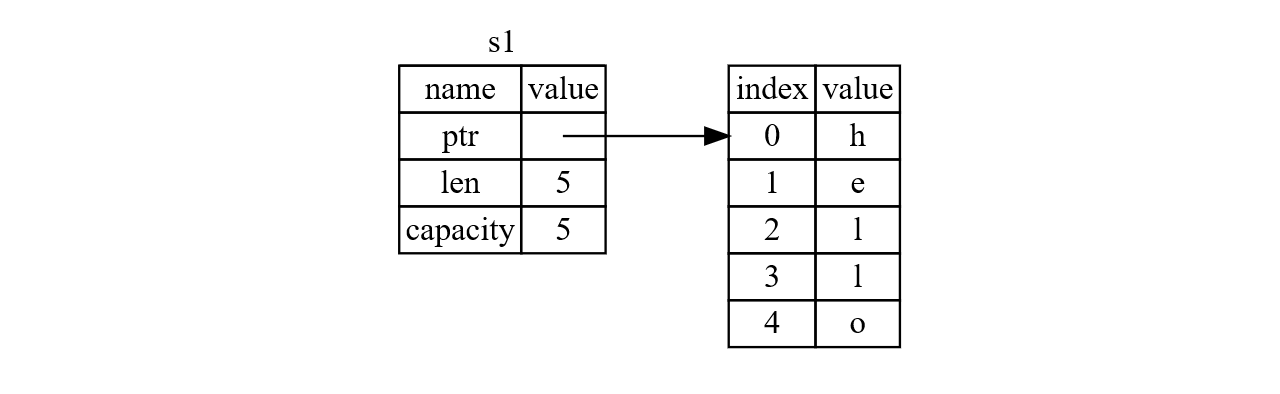
我们如果使用 copy 将 String s1 复制给 s2,我们实际上就将三个 field 的值 ptr、len 和 capacity 全部复制,也就是我们的 ptr 指针实际上指向上一块地址空间,如下图所示:
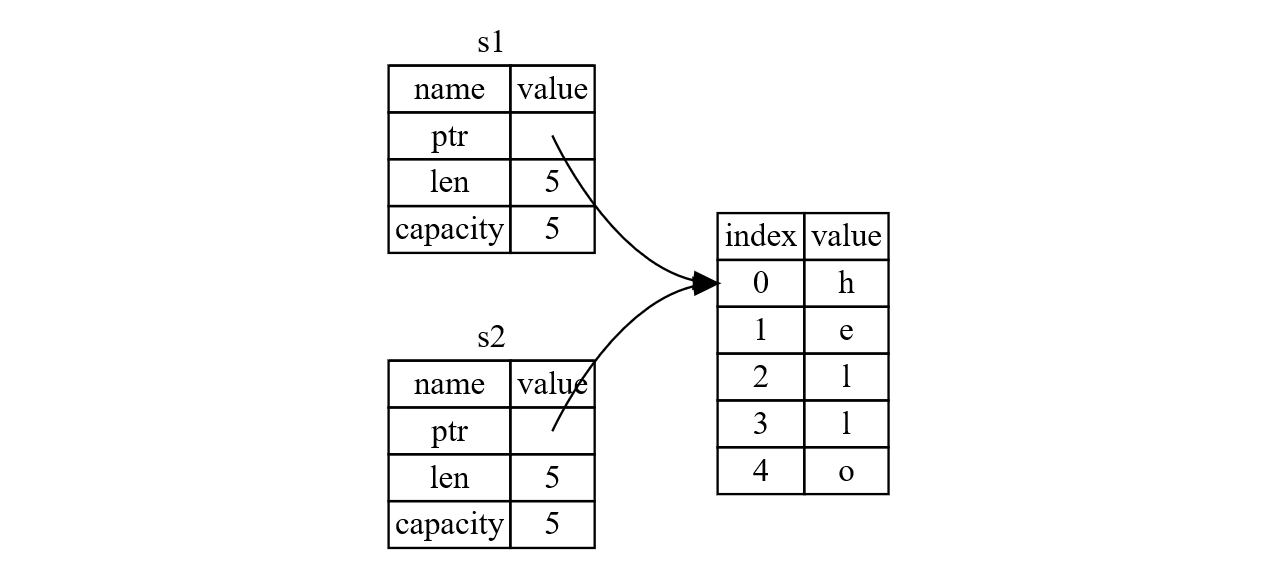
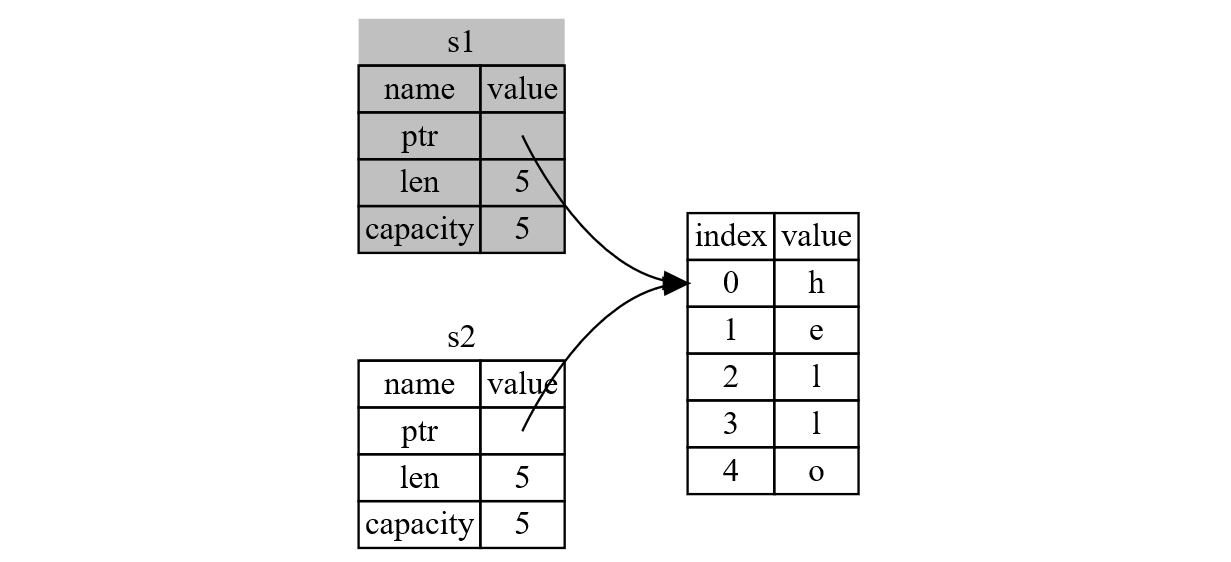
前面我们提到了,对于一个「值」来说,当程序离开「值」的 owner 所在的 scope 之后,这一「值」就会被释放掉,那么当我们离开 s1 和 s2 所在的 scope 之后,程序则会试图将这两个「值」的内存空间全部释放,而此时 s1 和 s2 指向同一块地址空间,这种情况下就会出现 double free 异常的情况。
Freeing memory twice can lead to memory corruption, which can potentially lead to security vulnerabilities.
而我们 Rust 就通过「所有权」规避了这一问题,如下图所示,Rust 在上述过程中,实际上是将 s1 的值移动到了 s2 上,在 s2 的指针指向对应的内存空间时,Rust 会认为 s1 此时已经无用了,从而直接 invalidate 掉 s1,那么当我们程序离开当前 scope 后,valid 的「值」只有 s2,Rust 就只会将 s2 释放,从而避免出现 double free 异常的情况。
不过,如果我们此时一定要访问 s1 的内容怎么办?Rust 有一个专门的方法,让 s2 创建时,不 move 而是深度拷贝 s1 的全部内容,如下图所示:
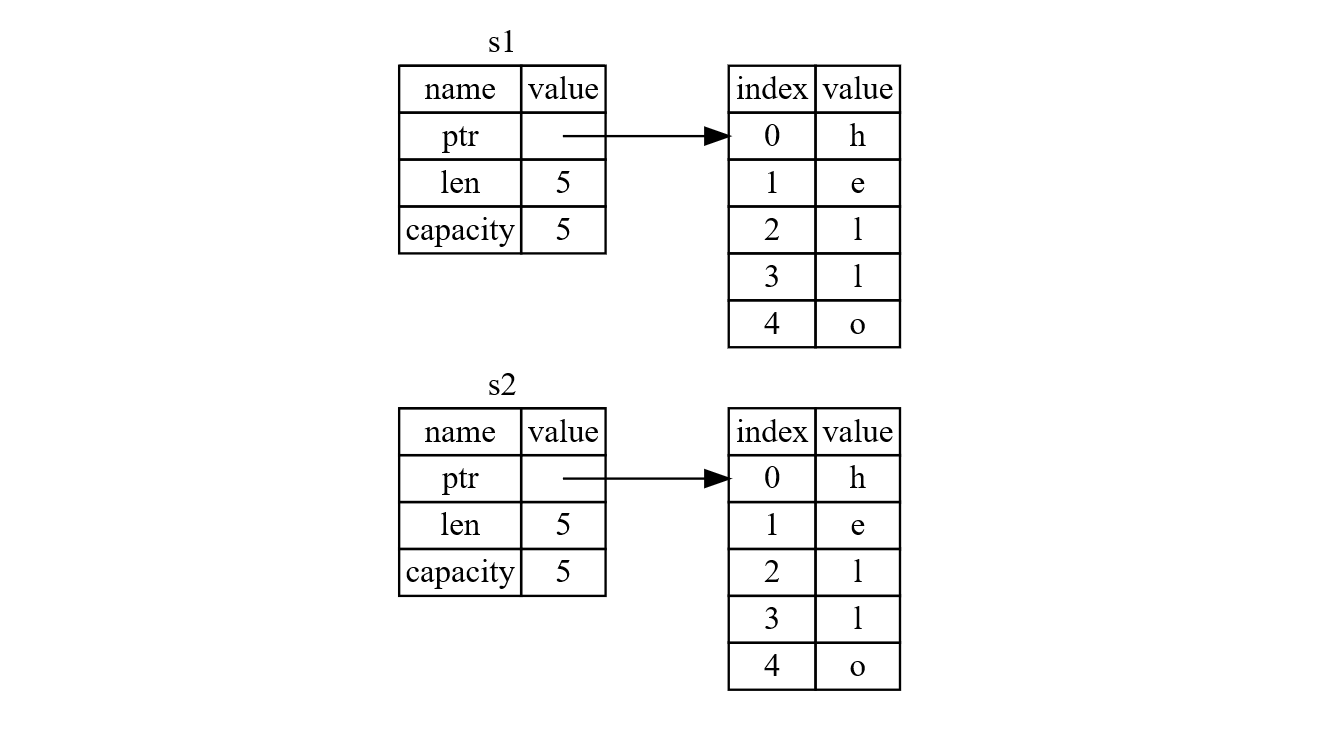
这里 Rust 所做的事情类似于其他语言中的 deep copy —— 花费更大的开销,将 s1 字符串对应的「堆」复制一个,再分配内存空间存储复制出来的 s1 并将之赋给 s2。在 Rust 中我们可以用 <VARIABLE>.clone() 来表示这一功能:
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
}上面的代码就不会出现类似的错误了。Rust 语言对「动态」数据结构都有类似的功能安排:利用 Ownership 的设计思想,在没有垃圾回收的基础之上,避免内存错误。
小结
Rust 的确是一门神奇的语言,不仅拥有 C、C++ 等系统级别语言的高效迅速,还利用 Ownership 的设计思想保证了内存安全。上面仅仅是 Rust 语言中一个小小的独特之处,由于这一特性所保证的功能我在其他语言中也有过类似的体验(比如 Python 的 deep copy 与 shallow copy5),因此拿来和大家分享。Rust 还有更多有趣的设计与内容等待大家发掘。感谢阅读。
