Time Complexity:CPython 实现的 Python 操作的时间复杂度

🧊 我算法实在太菜了,本文部分内容可能是小学二年级就应该知道的东西,所以如果各位大佬看到这篇文章的话,就当看个乐呵,还请不要嫌弃 555。(⊙﹏⊙)
这篇文章起源于各大 OJ 平台可能是最经典的一道题:Two Sum(两数之和)。我已经很久很久(可能已经有两年了)没做算法题了,由于我之前的项目里面其实很少涉及到一些比较复杂的算法,各个语言和框架的封装也让我对具体程序逻辑的优化放松了警惕,导致我对我写的代码的性能非常不敏感。于是我在前几天准备秒掉 TwoSums 的时候,就出现了极为尴尬的情况(提交顺序自下而上):

感觉自己被自己的水平羞辱到之后,我开始仔细找到 Python 官方文档里面对各个 native 数据结构操作的时间复杂度介绍,并也着手尝试通过巧妙的办法寻找时间优化方法,于是便有了这篇文章。
基础知识
CPython
先来介绍一些基础知识。Python 是一门动态语言(Dynamic language),也就是说:Python 在执行过程中是 Python 解释器对每一条 Python 代码进行翻译再运行,而不是像静态语言,比如 C、C++ 等,被编译为 native binary 后再执行的。其中,CPython 就是一个用 C 语言实现的 Python 解释器,也就是我们默认从官网安装 Python 时得到的那个最传统、最经典的 Python 解释器(但是性能表现并不算优秀)。
时间复杂度
为了准确的表达或衡量我们算法的执行时间,我们常常采用大 O 表示法,也就是 Big-O notation,来表达时间复杂度。比如 表示常数时间、 表示对数时间、 表示线性时间,等等。
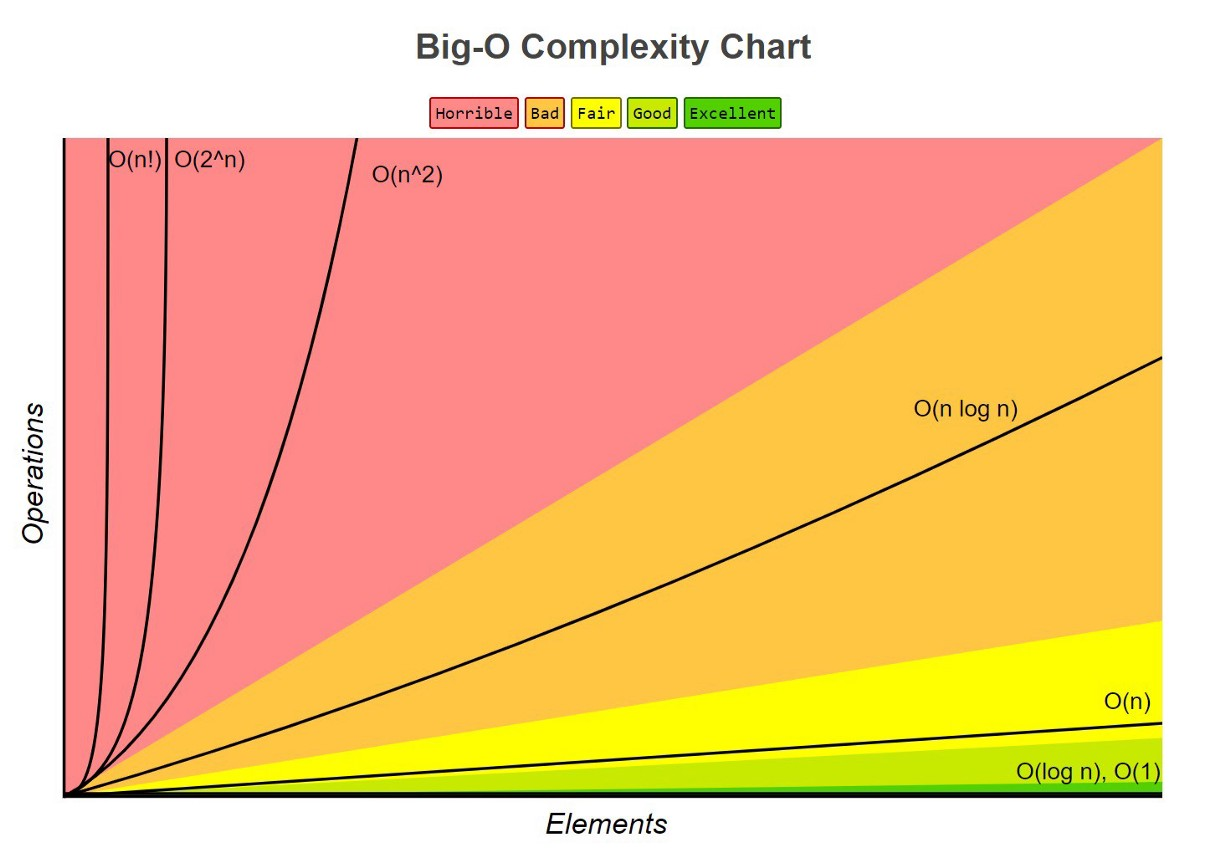
CPython 实现的 Python 操作的时间复杂度
CPython 是 Python 官方的解释器,也是我们最为常用的 Python 解释器。我重点研究了官方给出的 CPython 实现的几个 Python 原生数据结构操作的时间复杂度1,本文我把重点放在列表 list 和字典 dict 这两种数据结构上。
列表 list
Python 中的列表 list 是一个非常典型的数据结构,也是我们在 Python 里面最常用的一个数据结构。内部实现中,Python 的列表是用动态数组 — dynamic array2来实现的(而非链表)。在 CPython 中,Python 的列表实际上这样的一个 C 语言结构体:
typedef struct {
PyObject_VAR_HEAD;
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;其中,**ob_item 是指向列表中每个项目的一组指针,allocated 是为列表在内存中分配的空间格数(可以理解为一个列表项目一格)。
CPython 实现的 Python 列表数据结构决定了 Python 列表各种操作的时间复杂度。很容易理解下面常见的「列表操作」的时间复杂度6:
- 向列表末尾插入元素
.append(x)、移除列表末尾元素.pop()的时间复杂度为 ; - 向列表中任意位置插入元素
.insert(idx),移除列表中任意元素.remove(x),移除列表中任意位置的元素.pop(idx)的时间复杂度为 ; - 查询列表包含 / 不包含元素:
x in/not in l时间复杂度为 (线性查找); - 典型的列表排序
.sort()的时间复杂度为 。
字典 dict
字典,也就是 Python 的 dictionaries —— dict,是一种索引数据结构,且是通过 dict 的键 —— keys 进行索引,我们可以将其看作是关联性数组(Associative arrays)。在 CPython 内部,dict 是利用 Hash Table(哈希表)来实现的,也就是说:Python 字典是一个数组,其索引是使用每个 key 上的哈希函数获得的。
另外,实际上在 Hash Table 中,当我们使用一些较为复杂的随机哈希函数时,我们的主要目的是为了让设定的 key 的哈希能够在数组中均匀分布,同时最小化哈希冲突(Hash collisions),避免多个 key 对应同一个哈希值。然而 Python 的哈希函数实现则比较简单,实际也并不具备这种特性,我们可以尝试:
# Hash integers
list(map(hash, (0, 1, 2, 3)))
# Hash strings
list(map(hash, ("a", "b", "c", "d")))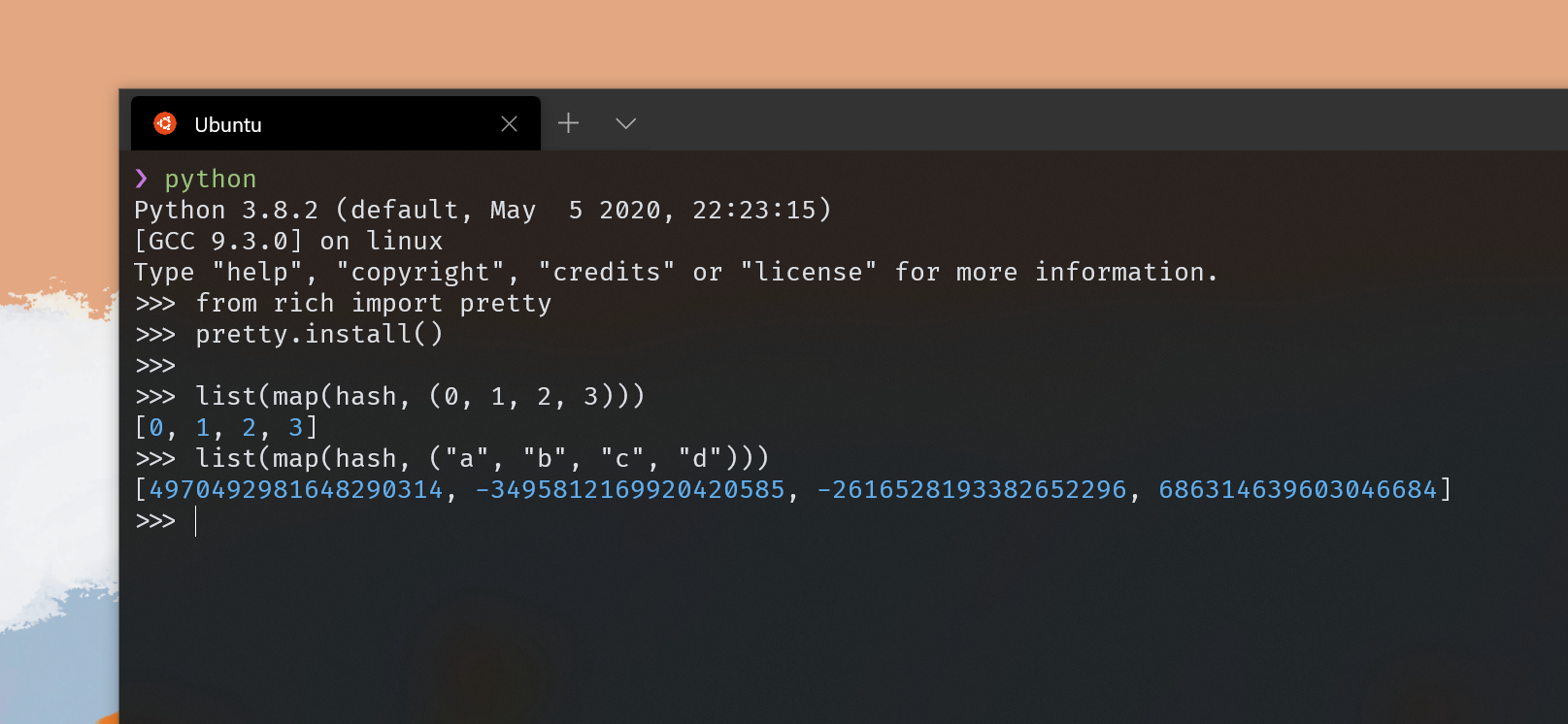
不过,Python 在 dict 中所使用的这样的 hash 函数,对于常见的具有连续 key 的 dict 则是被证明非常高效,不容易产生冲突的。当然,冲突还是避免不了,因此 Python 在 dict 实现中为了解决冲突(Collision resolution),会通过「开放地址法」来为冲突地址重新分配3。
好了,讲了这么多,我们的重点还是在于 Python 字典数据结构存储「键值对」的哈希表 Hash Table 实现。在实际 CPython(以及 PyPy4)中,Python 字典是使用如下的 C 语言结构体定义的:
struct dict {
long num_items;
variable_int *sparse_array;
dict_entry* compact_array;
}
struct dict_entry {
long hash;
PyObject *key;
PyObject *value;
}其中的 dict_entry 就是存储我们字典中「键值对」的数据结构了。使用 Hash Table 实现的 dict 字典能够极为高效的实现数据存取,也就是说6:
- 根据
key获取字典中的value的d[k]或d.get(k)时间复杂度均为 ; - 设定某个
key的值value的d[k] = v的时间复杂度也为 ; - 查询字典中是否包括某个
key的k in/not in d的时间复杂度依旧为 ; - 甚至于获取整个字典的全部
keys的d.keys()的时间复杂度还是 !
大部分 Python 字典的操作时间复杂度都是 的,因此使用「字典」作为我们的数据载体往往能够极大的提升我们算法的执行效率。当然,其他语言的 Hash Table(比如 Java 的 HashSet、JavaScript 的 Object)实现同样也有类似的效果。
疏忽导致的性能问题和解决措施
用 index() 寻找列表中的元素序号
讲完了 CPython 内部的列表与字典的实现,我们回到最初那道算法题。Two Sum 这道题本身其实非常简单,其中要求返回的是取得的两个数字在原列表中的 index:
..., return indices of the two numbers such that they add up to a specific target.
当时我并没多思考性能问题,为了简单的用一个函数同时判断数字是否存在于列表中,并返回数字在列表中的 index,我大胆使用 .index()!
# ...
try:
partner_idx = nums.index(partner)
if idx == partner_idx:
continue
return [idx, partner_idx]
except ValueError:
continue
# ...Python 列表的 .index(x) 方法会遍历整个列表,并返回所求元素 x 第一次出现的 index,如果没有找到,那么会 raise 一个 ValueError。请大家看,我这里为了能用上 .index() 方法,甚至直接用 try except 异常处理来写,太憨憨了。.index(x) 需要遍历整个列表,因此这部分的时间复杂度是 的,整个算法的时间复杂度就趋近于 ,我的第一发 1224ms 的憨批运行时间也主要耽误在这里了。使用 dict 实现一个查找表,使用 的时间,一次遍历即可完成查询:
# ...
if num not in lookup_dict:
lookup_dict[partner] = idx
else:
return [lookup_dict[num], idx]
# ...用 d.get(k) 与 d[k] 对字典进行访问
除了上面这个问题以外,在使用 Python 字典的时候我还遇到了这样的问题。我们都知道其实根据键 k 来访问 Python 字典对应的值 value 时,用 d.get(k) 相比直接用 d[k] 算是更为优雅的一种方法5:
- 我们如果直接用
d[k]访问一个不存在的k,那么运行时 Python 会 raise 一个KeyError的错误,而d.get(k)则会优雅的返回None; - 我们可以通过
d.get(k, default_value)的语法来设定一个默认值,当k不存在时返回这一值即可;
习惯于「优雅的解决方法一定更好」的我,在算法题里面同样用了 d.get(k) 来获取字典中的 value,但是我发现这样的方法要比同样的 d[k] 慢很多(提交顺序自下而上):
![80ms 的提交使用的是 .get(k),而 48ms 的提交使用的是传统方法 d[k]](https://cdn.spencer.felinae98.cn/blog/2020/08/200820_010904.png)
当然,不用说我们也知道主要因为 Python 的 d.get(k) 实现中需要处理更多的事情,同时 get() 还是一个函数调用,需要入栈出栈,肯定会消耗更多的时间。因此,这里更需要我们注意,如果我们希望编写效率最高的代码,那么一定需要考虑这些会触发性能瓶颈的问题。
🍫 注意
但是我这里并不是在说 d.get(k) 方法不好,只是在「时间敏感」的地方,我们可以通过优化这种调用来大幅度提高我们程序的运行效率。
小结
最初的时候我做算法题大部分都是用 C++ 编写的,从来都没尝试过用像 Python 这种抽象程度这么高的语言来做算法题。因此如果想要追求高性能,除了对数据结构有充分的了解,还需要对自己所使用语言的内部实现有所认知。我们在使用高级语言实现某些算法中,使用很多封装好的方法时,都需要对「算法本身」和「所使用的方法实现」这二者更深刻的认识才能最大化的发挥他们的功力。当然,使用 Python 来写算法题更多的还是快乐,比如:「哎!这也能直接用!那也能直接用!快排都不用我手写了!」开心 ~ 好啦,文章就到这里,感谢大家的阅读!
