论文阅读:Nesterov Accelerated Gradient And Scale Invariance For Adversarial Attacks

这周组会分享了一篇论文:Nesterov Accelerated Gradient And Scale Invariance For Adversarial Attacks。这篇论文是一篇 ICLR 2020 的文章,作者是华中科技大学、北京大学和康奈尔大学的实验室。主要提出了 NI-FGSM 和 SIM 两种 Transfer-based 黑盒攻击。
论文贡献
🍗 主要贡献
In this work, from the perspective of regarding the adversarial example generation as an optimization process, we propose two new methods to improve the transferability of adversarial examples, namely Nesterov Iterative Fast Gradient Sign Method (NI-FGSM) and Scale-Invariant attack Method (SIM).
论文在将对抗攻击过程看作是一个「优化的过程」,基于提升对抗样本可迁移性的考虑,提出了 NI-FGSM 和 SIM 两种对抗攻击方法:
- 论文在基于梯度的迭代对抗攻击中,使用 NAG 进行优化,从而更有效的实现 Lookahead,使得对抗样本的 transferability 增强。论文认为:NI-FGSM 最终能够有效代替 MI-FGSM(或者 MIM — Momentum Iterative Method)
- 论文认为深度学习模型具有 Scale-invariant 的特性,因此提出 Scale-Invariant Method:用多组尺度缩放的输入图像来优化对抗扰动,有效抑制白盒模型过拟合问题,从而得到针对黑盒模型易迁移的对抗样本
- 将 NI-FGSM 和 SIM 与现有基于梯度的攻击方法(比如 TIM、DIM)结合,可以有效提升对抗攻击成功率
论文实验表明,在这两种方法和已有方法结合之中,SI-NI-TI-DIM 这种方法的攻击性能最好,平均攻击成功率能够达到 93.5%.
对抗攻击算法设计
算法设计思路
首先,论文将「Transfer-based 黑盒对抗攻击」的过程和「常规训练图像分类模型」的过程,看作是一致的优化过程 — Optimization process。在常规训练模型的过程中,我们通常有这样的步骤:

那么,与之相对应的,在 Transfer-based 黑盒对抗攻击中,我们同样有这样的步骤:

非常容易发现,在这两个过程中:
- 「模型训练」过程中的「训练数据集」就相当于「Transfer-based 对抗攻击」中的「白盒模型」
- 「模型训练」过程中「根据训练数据优化待训练参数」就相当于「Transfer-based 对抗攻击」中「根据白盒模型优化生成对抗样本」
- 那么,「模型训练」过程中的「测试数据集」就相当于「Transfer-based 对抗攻击」中的「黑盒模型」,依次用于「评估模型的性能」和「评估攻击的性能」
那么,从同样「优化」的角度来看,提升对抗样本 transferability 和增强被训练模型的 generalization ability(泛化能力)的方法应该是类似的,因此论文考虑使用增强模型泛化能力同样的方法来增强对抗样本的可迁移性。
| 增强模型泛化能力 | 增强对抗样本可迁移性 | |
|---|---|---|
| 更好的优化算法 | 在图像分类模型中,使用 Adam Optimizer 实施优化 | 在 MI-FGSM 攻击中,通过引入 Momentum 帮助优化 |
| 输入增强 | 数据增强 Data Augmentation | 模型增强 Model Augmentation(比如同时攻击多个模型的 ensemble attack) |
基于以上的论断,论文考虑以下两种改进,以增强对抗样本的可迁移性:
- NI-FGSM:使用更好的优化算法。论文使用 NAG — Nesterov accelerated gradient 来优化基于梯度的迭代攻击
- SIM:实施模型增强。论文考虑使用一系列被缩放的图像训练模型,从而达到 Model Augmentation 的效果
NI-FGSM
Nesterov Accelerated Gradient 是普通梯度下降法(Stochastic gradient descent)的轻微修改,可以有效加速训练过程,大幅度增强收敛能力。NAG 可以看作是基于 Momentum 的优化的改良版:
论文发现普通基于梯度的迭代攻击(I-FGSM)非常容易陷入局部最优,导致比单步攻击(FGSM)可迁移性差。实验表明向迭代攻击中引入 Momentum 可以有效解决这一问题(MI-FGSM)。于是,论文考虑向迭代过程中引入 NAG 实施优化过程:
- NAG 除了可以帮助稳定迭代更新的具体方向,NAG 的预期更新还可以给先前积累的梯度以纠正,进而实现 lookahead 特性
- 借助 lookahead,NI-FGSM 能更快逃离局部最优,从而大幅加强攻击性能和可迁移性
具体实现:
其中, 表示第 次迭代时累积的梯度, 表示 的衰减系数。
SIM
和模型泛化可以通过增添更多训练数据来优化类似,对抗样本的可迁移性也可以通过同时攻击更多模型来增强:
- 论文提出使用 Loss-preserving transformation 获得更多模型的方法,可以减少训练模型的开销
- 论文认为模型具备 Scale-invariance 特性:输入图像与其缩放后得到的图像相比,二者反映在模型上的损失是相近的。因此论文使用缩放变换 scale transformation 作为模型增强的方法
综上,论文提出了 Scale-Invariant attack Method(SIM):
其中, 表示输入图像 在缩放系数 下得到的缩放图像。这样,我们利用 SIM 就可以用尽可能小的开销实现模型增强,有效开展同时针对多个模型的 ensemble attack。同时,还可以让白盒模型避免过拟合问题,生成具备更好迁移性的对抗样本。
SI-NI-FGSM 算法
将 SIM 和 NI-FGSM 结合,就得到了 SI-NI-FGSM 攻击,基本算法如下。

评估方法与实验数据
论文选择从 ImageNet ILSVRC 2012 测试数据集中随机选择 1000 个分类中的共计 1000 张图片作为图像数据集,确保图片几乎全部被测试模型正确分类。选择依次对比 TIM、DIM、TI-DIM 三种基准攻击以及将 SIM、NI-FGSM 与这三种攻击相结合的 SI-NI-TIM、SI-NI-DIM 与 SI-NI-TI-DIM 进行比较。
验证图像分类模型 Scale invariant 的性质
首先论文随机选择 1000 张 ImageNet 的原始图片,将缩放比例设置为 [0.1, 2.0]、步长 0.1。缩放后图像作为输入送入测试模型 Inc-v3、Inc-v4、IncRes-2 和 Res-101 中,得到 1000 张图片的平均损失:
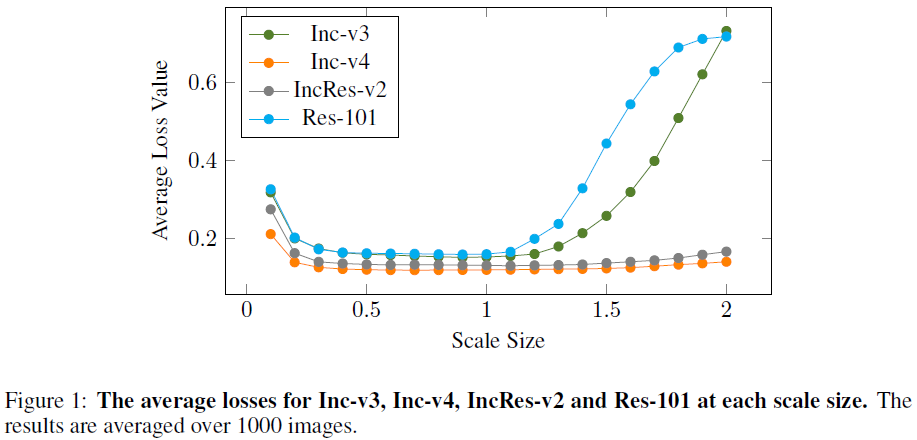
论文发现损失在缩放比例为 [0.1, 1.3] 之间时是稳定平滑的,即原图和缩放 [0.1, 1.3] 倍数后图像相比损失相近。为了能够在优化对抗扰动过程中利用模型 Scale-invariant 性质,实验控制图像的缩放比例在 [0.1, 1.3] 之间。
攻击单个模型
论文将 SI-NI-FGSM 和基准攻击 TIM、DIM、TI-DIM 分别依次整合,并比较单模型攻击设定下黑盒攻击的成功率(%),得到如下的实验结果。
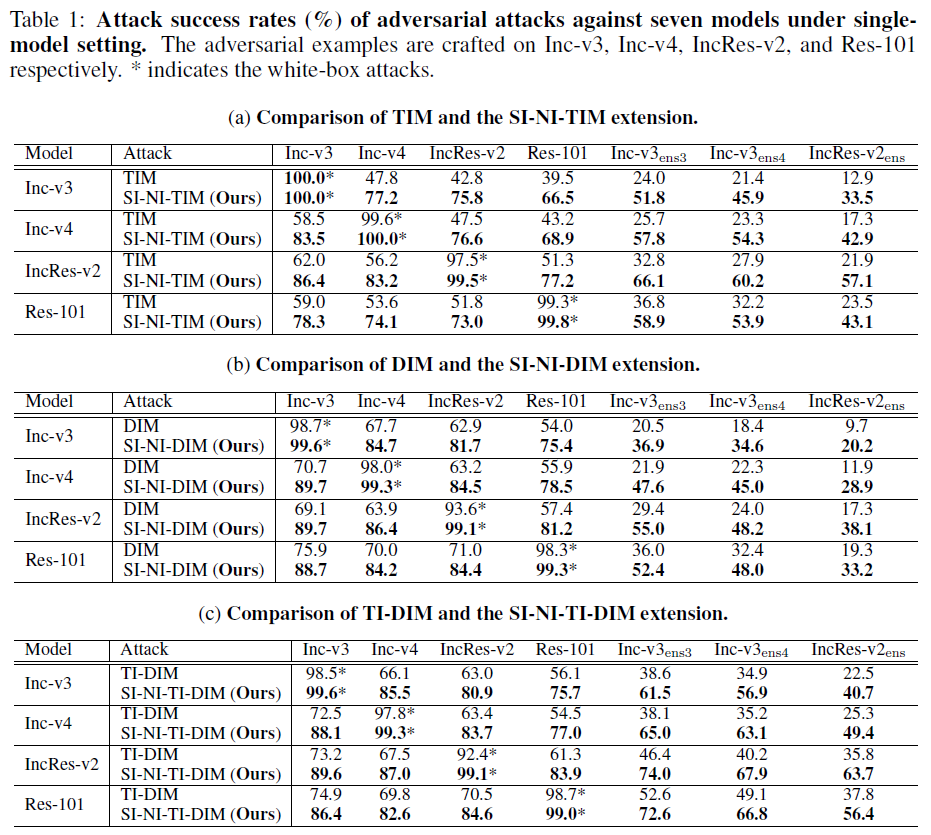
可以发现:
- 论文方法(SI-NI-TIM、SI-NI-DIM、SI-NI-TI-DIM)比基准方法黑盒攻击成功率始终稳定提升 10%-35%
- 白盒攻击设定下,论文方法甚至可以直接达到 100% 的攻击成功率
攻击集成模型
论文继续使用论文(TIM、SI-NI-TIM;DIM、SI-NI-DIM;TI-DIM、SI-NI-TI-DIM)攻击方法分别同时攻击一组相同 ensemble 权重的集成模型(Inc-v3、Inc-v4、IncRes-v2 和 Res-101):
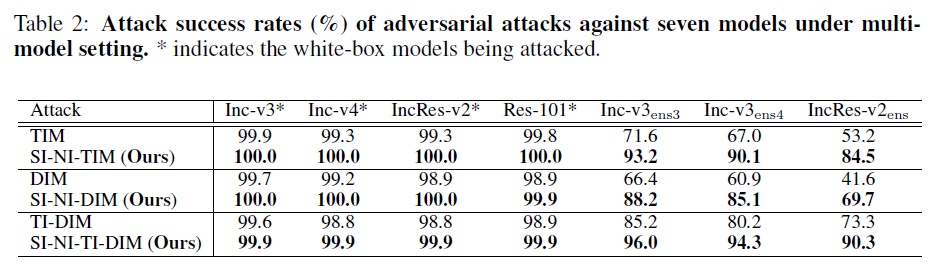
可以发现:
- 黑盒设定下,论文攻击方法比基准攻击的攻击成功率高出 10%-30%
- 其中,SI-NI-TI-DIM(SI-NI-FGSM 和 TI-DIM 结合)可以达到 93.5% 的成功率
攻击其他防御模型
论文继续尝试攻击其他性能更好的防御模型:
- 包括 NIPS 比赛中排名前三的防御模型:HGD、R&P、NIPS-r3
- 以及最近提出的三种防御方法:Feature Distillation、Comdefend、Randomized Smoothing
论文将 SI-NI-TI-DIM 和 MI-FGSM、TI-DIM(目前性能最好的基于迁移的黑盒攻击)进行对比,使用这三种攻击分别在 Inc-v3、Inc-v4、IncRes-v2 和 Res-101 集成模型上生成对抗样本,并用生成的对抗样本攻击上面的防御模型。
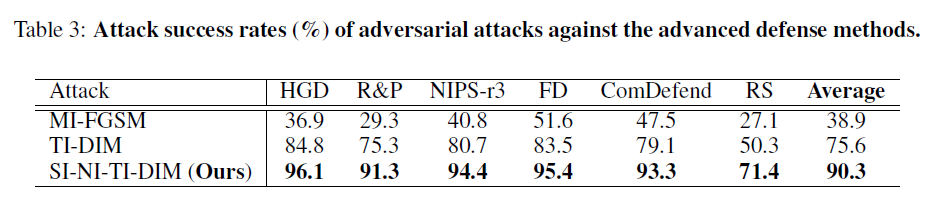
最终实验表明:SI-NI-TI-DIM 达到平均 90.3% 的攻击成功率,比目前先进的攻击手段高出 14.7%.
进一步分析
论文进一步对比了 NI-FGSM 和 MI-FGSM,使用 Inc-v3 模型迭代 4 至 16 次生成对抗样本,迁移攻击 Inc-v4 和 IncRes-v2 模型的成功率。
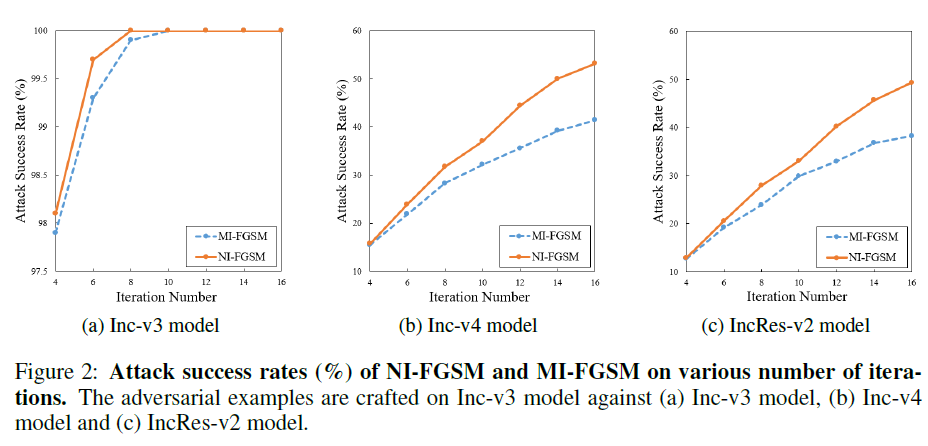
分析发现:NI-FGSM 在相同的迭代次数下能获得比 MI-FGSM 更高的攻击成功率。也就是,NI-FGSM 用更少的迭代次数就能达到和 MI-FGSM 相近的性能。
因此,NI-FGSM 不仅比 MI-FGSM 有更好的迁移性,还有更高的攻击效率。
Nesterov Accelerated Gradient
全因为 NAG 这个优化算法啊!NAG 虽然只比 Momentum 优化多了一步,相当于根据前方的梯度地形,多走一步,但正因为这一步,让 NAG 比 Momentum 优化收敛的更快。1
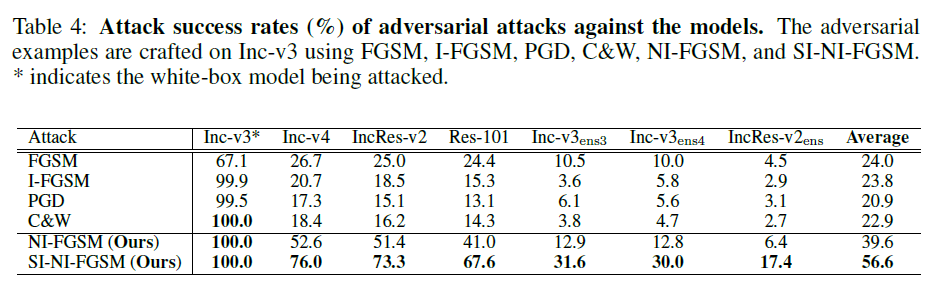
同时,论文还和 FGSM、I-FGSM、PGD 和 C&W 传统攻击进行了对比,实验表明 NI-FGSM 和 SI-NI-FGSM 在白盒设定下和 C&W 一样能够达到 100% 的攻击成功率,黑盒设定下性能远远超越其他攻击。
结论
论文贡献:
- 论文提出 NI-FGSM 和 CIM 两种方法以及它们的组合方法,来提升对抗样本可转移性
- 实验表明,将 SI-NI-FGSM 和其他方法结合,能进一步提升攻击性能,成功攻击其他强防御方法
论文认为:
- NI-FGSM 能够成功提升攻击成功率表明其他优化方法(比如 Adam Optimization)也可能有助于构建强对抗攻击
- 神经网络模型存在 Scale-invariant 性质,但目前未找到确切存在原因。作者认为可能由于模型每一卷积层的 batch normalization(批量正则化)导致模型对尺度变化不敏感
